


【自有技术大讲堂】数据驱动的AI(系列1)— AI数据增强浅析
一、数据增强--用以增强不够完美的现实世界数据
在现实世界中应用人工智能的许多挑战主要原因都是数据不够完善。现实世界中的数据包含了各种各样的限制,如图1所示:
1)领域差距(Domain gaps):用来训练模型的数据与在现实世界中必须预测的数据有很大的不同。
2)数据偏差(Domain bias):当收集的数据由于社会偏差而出现不平衡时,该如何设计能够克服它们的方法?
3)数据噪声(Domain noise):噪声可以来自各种来源,包括标签不明确、杂乱或损坏的地方。
鉴于这些不完美给人工智能系统带来的不确定性,那么模型如何还能学习到健壮的特征表示呢?特别是如果人类对大容量数据集进行人工标记的代价很高,如此一来,挑战就变成了是否可以在没有任何标记的情况下克服这些问题。
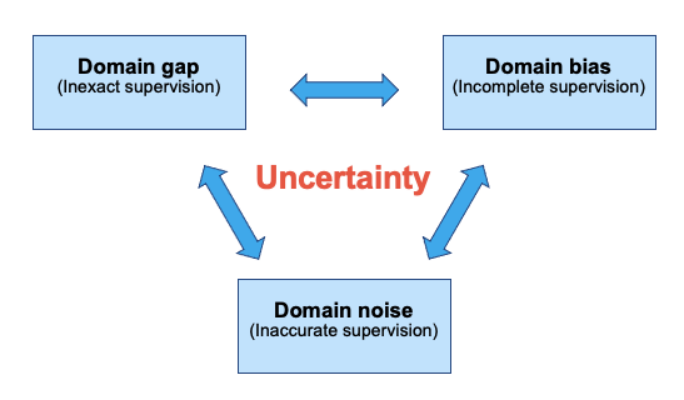
图1.真实世界数据中的不确定性
二、什么是数据增强?
数据增强也叫数据扩增,意思是在不实质性的增加数据的情况下,让有限的数据产生等价于更多数据的价值。可以使用各种各样的技术来克服上述这些不确定性。数据增强可能是最简单的方法之一,它通过添加额外的训练数据来实现:
自我监督:当仅仅拥有有限的标签数据时,可以尝试将其与未标签的数据相结合。可以创建数据的扩充,如果标签对所有这些转换都是不变的,则已经基于这些不变性创建了监督。例如,图像的分类对于旋转或裁剪等变换是不变的。在许多分类任务中,使用这种类型的学习甚至超过了监督学习。
合成数据:另一种方法是将有限的标签数据与合成数据结合起来。虽然合成数据还处于初级阶段,但生成模型已经取得了进展,未来它将对自动驾驶或机器人学习等测试系统产生非常重要的影响。
三、数据增强中的数据中心原则
数据增强的核心设计是在平衡积极和消极例子。考虑图像识别,比如从一只猫的图像开始,如果做一组改变,如旋转图像或改变对比度,预测保持不变,就有了一个积极的例子。一个消极的例子是,如果做了其他改变,比如选择了一个不同的图像,预测就会改变。最后,需要对比这些积极的例子和消极的例子,特别是那些相互接近的例子,以便了解分类器的边界应该在哪里。这些对比学习原则是MOCO和SimCLR等流行方法的基础。

图2.使用SimCLR创建正例和负例来学习分类器边界
更好的是可以将自我监督与弱监督结合起来——为相关任务贴上标签,这通常比人类标签要求要低得多。最近有一种叫做Discobox的技术,在这种技术中,只在训练数据中使用边界框标签来训练模型进行实例分割和对应学习。 有边界框标签通常是一种更低价且便利获得的标签形式。
作为一个现实世界的案例研究,研究者正在努力扩大这些技术,以降低自动驾驶的标签成本。该模型在YouTube上的随机视频和自动驾驶视频上进行了测试——这些视频与训练的视频完全不同——并展示了高质量的即时分割结果,如图3所示。

图3.即时分割在一个完全不同领域的模型是可以只使用包围框作为标签训练的
在使用自我监督等方法时,无需创建任何更多的标签,便可以克服许多领域的标签稀缺的问题。最近在这一领域已经取得了很大的进展,但也有更多的进展有待取得。例如,虽然合成数据仍处于初级阶段,但在未来,它将对自动驾驶或机器人学习等测试系统变得极其重要。
还有另一种形式的数据扩展,可以从在一个领域中训练模型开始,这个领域与它将被部署的领域是完全不同的。通过在合成域中使用正负情况,从容易的情况逐步学习到困难的情况,可以通过调整从合成域中学习的分类边界,过渡到现实世界!另外,将合成数据添加到有限的数据中并非不复杂。虽然合成数据可以足够逼真,甚至人类都无法区分模拟和真实数据,但就场景分布而言,仍然会迎来巨大的变化,所以需要技术以一种高度可控的方式生成数据。
人工智能系统需要数据,因此需要在这方面和其他许多方面进行更多创新,以帮助克服现实世界数据的缺陷。
四、高视科技的AI数据增强方式介绍
众所周知,AI模型的性能优异与数据的质量和数量息息相关。我们为了达到模型的最佳性能,开始训练之前,通常会对待检测的图像进行大量缺陷形态和位置分析,这一步骤必不可少,否则会大大增加后续的数据收集与处理的耗时。
以屏幕缺陷检测为例,当遇到图像基本不受翻转的影响,我们会优先利用上下翻转(vertical_flip)和水平翻转(horizontal_flip),如下图所示:

图4. 依次为原图,左右翻转图,上下翻转图
我们发现尽管缺陷的位置发生改变,但是缺陷其实均为脏污,而且脏污的形态本身是千变万化的,位置也不固定,如此一来,此类的数据增强非常适合应用于当前场景。翻转是非常通用的数据增强方式,但也有一些场景目标的形态位置是固定的,背景具有明显的位置信息,导致上下翻转或者左右翻转,比如说草地上的一只小狗,左右翻转是没问题的,但是上下翻转就会出现不符合逻辑和常规的状况,因为小狗通常是不会颠倒过来的,草地也不会。
针对部分缺陷原始数据较少,且形态不是很明显的情况,我们会使用其他的数据增强,比如改变图像对比度,在不会破坏缺陷形态的基础上,能增加图像图像的数量,比如MURA类的缺陷,如下图所示:

图5. 左为原图,右为对比度增强图
图5中,原图中的白色mura区域并不明显,尤其是放大之后,肉眼很难区分,因此增加了数据获取的难度,针对这种情况,我们增加了对比度,由于背景的像素值通常也会有波动的情况,配合上其他的一些增强方式,能增加一些严重缺少样本的缺陷图像,提升模型的精度。
在以往的多种环境中,我们使用了包含但不限于以上的常见的数据增强方式,比如:随机裁切(random crop)、随机旋转(random rotate)、通道偏移(channel shift)、错切变换(shear range)、随机拉伸(random zoom)以及图像融合(MixUp)等等。
值得一提的是,随机使用这些数据增强的方式,往往并不会带来模型泛化性能的提升,反而可能会降低其性能,出现模型严重的过拟合。因此我们需要因地制宜,从实际的图像出发,分析图像可能的形态,以及符不符合现实的状况,选择合适的数据增强方式,只有这样才能达到事倍功半的效果!
五、总结
在深度学习工业化的时代,数据的规模越大、质量越高,模型就能够拥有更好的泛化能力,数据好坏直接决定了模型学习的上限。在实际工程中,采集的数据很难覆盖全部的场景,那么在训练模型的时候就需要加入合适的数据增强方式。另一方面,即使拥有大量的数据,也应该进行数据增强,这样有助于添加相关数据集中数据的数量,防止模型学习到不想要的特征,避免出现过拟合现象。







