


【自有技术大讲堂】数据驱动的AI(系列9):通过误差分析提高模型性能
一、引言
错误分析是检查算法错误分类的图像示例的过程。通过此分析,能够了解错误的根本原因,从而可以确定优化模型和提高性能的最佳步骤的优先级。
在训练AI模型之后,将在验证集上验证性能。在理想情况下,模型在验证集上表现良好并实现了初步目标。通常情况下,会存在性能差距,所以需要改进模型。可以从各种工具和技术中选择,包括数据增强、超参数优化或可能的新架构。了解如何缩小错误差距并提高性能的最快方法是不断尝试应用小的而孤立的更改,并直接解决最大的错误。选择快速测试并直接解决对总体错误贡献最大的特定类型错误的方式,而不是进行彻底的更改。
我们将使用一种简单的错误分析形式来实现这一点:
1、检查验证集中大约100张模型出错的图像。
2、将每个图像放入一个或多个表示不同潜在错误源的桶中。例如,自动视觉检查可能包括:“图像失焦”、“缺陷很小”和“照明发生变化”。
3、选择包含最多图像的一个或两个存储桶。
4、建议更改以直接解决该错误。
5、重新训练模型。
6、将新模型的性能与当前模型的性能进行比较。
误差分析提高了模型的性能。利用分析结果,可以更好的用于优化模型。这将创建一个更通用的模型,以更好地识别新图像。继续阅读错误分析示例。

二、分析训练集上的模型错误
在创建模型期间,我们使用数据集进行训练。以下是三种类型的数据集。
训练集-用于训练模型。
验证集-用于调整超参数、选择特征和做出关于学习算法的其他决策。
测试集-用于评估算法的真实性能,但不用于决定使用什么样的学习算法或超参数。
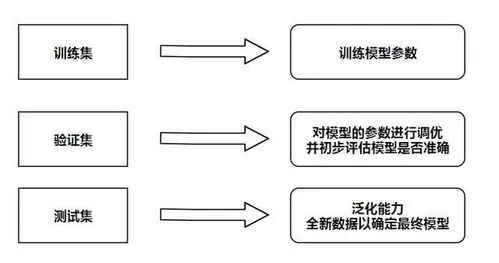
在错误分析过程中,我们使用前两种类型,即训练集和验证集。测试图像集独立于前两个图像集。我们不能在训练过程中包含测试图像。这将有可能过度拟合模型,导致性能不佳。目标是根据训练集数据制定一个通用的解决方案。
三、改善假阴性样例
我们的模型用于检测制造缺陷。在这种情况下,目的是正确识别有缺陷的零件,而错误的结果是识别出没有缺陷的零件。假阴性是指模型错误地预测零件没有缺陷,但实际上有缺陷的情况。假阴性是最坏的结果,因为这意味着向客户发送有缺陷的零件。
为了帮助解决这个问题,我们需要一个具有高召回率的模型。这将是一个具有高百分比正确识别缺陷的模型。
我们将研究使用错误分析快速提高性能的两个场景。比如训练一个物体检测模型来检测chip缺陷和scratch缺陷。每个部分都产生了一些图像,我们将其用于训练和评估。chip缺陷相对常见。scratch缺陷非常罕见,不到1%。
基线模型仅实现了74%的scratch缺陷召回率。在验证集的误差分析中,我们发现模型遗漏了严重的scratch缺陷。由于scratch缺陷很少,可以手动检查数据集中的分布。我们发现在训练集中没有严重的scratch缺陷。所有这些都分布在验证集和测试集中。
通常在训练、验证和测试集之间随机分割图像数据,以获得类似的分布。然而,由于严重的scratch缺陷非常罕见,因此由于随机选择,很有可能会问题。这使得训练集没有严重的scratch缺陷。
理想情况下,我们将收集更多严重的scratch缺陷的示例,以分发到训练集。由于稀有,这是不可行的。
在处理客户模型时,我们不受固定数据集的限制。客户数据集始终在增长,在这种情况下,在训练和发展之间移动分配图像是可以接受的。关键问题是不要影响我们的测试集性能,并确保在生产中获得最佳性能。
四、应用数据增强
在重新训练模型之后,我们重新检查了它的错误。现在的分析表明,它主要在图像边缘附近漏掉了scratch缺陷。这可以通过应用数据扩充来轻松解决。我们随机裁剪现有图像,以模拟更多缺陷最终出现在图像边缘的情况。
五、训练集的成本变化
我们考虑了一个更复杂的选项,例如切换到分段模型。这将在学习缺陷时为模型提供更多信息。我们甚至考虑通过生成合成缺陷来增加数据集的大小。这种变化需要大量的标签和工程费用。然而,这些方法都不能直接解决模型的错误。
六、小型和孤立实验
我们为解决目视检查中的错误编制了一个简短的建议表。在尝试更高级或更复杂的东西之前,应该首先尝试这些技术。虽然他们可能无法完全弥补性能差距,但应该可以很快缩小了可能的选择范围。

我们建议创建并共享自己的小型和独立实验表,在迭代模型时更新它。
七、结论
八、关键要点
评估模型时,将错误分组到桶中,找出最大的错误源。
通过小而孤立的更改快速弥补性能差距,以直接解决最大的错误源。








