


【自有技术大讲堂】数据驱动的AI(系列11):让人工智能使用小数据
随着制造商开始将人工智能解决方案集成到生产线中,数据稀缺已成为一个主要挑战。与拥有数十亿用户数据来训练强大人工智能模型的消费互联网公司不同,在制造业中收集大量训练集通常是不可行的。
例如在汽车制造业中,大多数原始设备制造商和一级供应商努力使每百万个零件的缺陷少于三到四个。这些缺陷的罕见性使得拥有足够的缺陷数据来训练视觉检查模型变得具有挑战性。
在最近的一项MAPI调查中,58%的研究受访者表示,部署人工智能解决方案的最主要障碍是缺乏数据资源。
规避小数据问题的技术
大数据使消费互联网公司实现了人工智能。那制造业能让人工智能使用小数据吗?事实上,人工智能的最新进展使这成为可能。即使只有几十个或更少的例子,制造商也可以使用以下技术和技术来解决小数据问题,以帮助他们的人工智能项目上线:
合成数据生成用于合成现实生活中难以收集的新颖图像。GAN、变分自动编码器、域随机化和数据扩充等技术的最新进展可用于实现这一点。
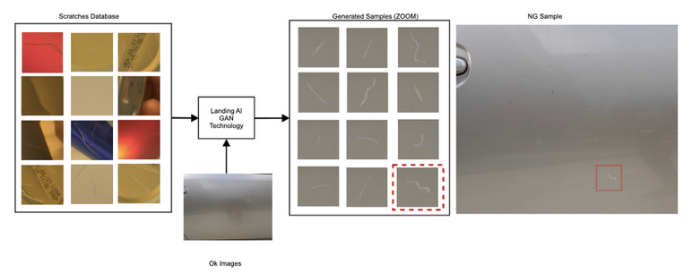 图1,利用GAN来生成标注
图1,利用GAN来生成标注
这些图像显示了合成生成的表面划痕数据。这些划痕从划痕数据库中转移,然后在干净的金属表面上分层。使用合成数据,可以为缺陷检测等任务训练强大的视觉检查模型,即使使用非常少量的缺陷数据集。
迁移学习是一种使AI能够从有足够数据可用的相关任务中学习技术,然后使用这些知识帮助解决小数据任务。例如,人工智能学会从从各种产品和数据源收集的1000张凹痕图片中找到凹痕。然后转移这些知识来检测特定新产品中的凹痕,可能只需少量凹痕图片用于新的训练集中。
自监督学习类似于转移学习。但是所获得的知识是通过解决稍微不同的任务来获得的,然后适应于小数据问题。例如,可以拍摄大量OK图像,并创建一个类似拼图的网格,以便按基础模型进行排序。解决这个虚拟问题将迫使模型获取可作为小数据任务起点的领域知识。
在few-shot中,小数据问题采取新的思路,以帮助AI满足更容易、更少数据需求的检查任务。在这种情况下,人工智能被赋予了数千个更容易的检查任务,其中每个任务只有10个(或另一个类似的小数目)示例。这迫使人工智能学会识别最重要的模式,因为它只有一个小数据集。之后,当模型暴露在重要问题中时,它的性能将受益于它完成了数千个类似的小数据任务。
One-shot学习是一种少次学习的特殊情况,每个类别需要学习的示例数量是一个,而不是几个(如上面的示例)。
在异常检测中,AI没有看到缺陷的例子,只有正常图像的例子。该算法学习将任何与正常图像显著偏离的内容标记为潜在问题。
Hand-coded knowledge(手工编码知识)就是一个例子,人工智能团队采访检查工程师,并试图将他们尽可能多的机构知识编码到一个系统中。现代机器学习一直倾向于依赖数据而非人类机构知识的系统,但当数据不可用时,熟练的人工智能团队可以设计利用这些知识的机器学习系统。
Human-in-the-loop(人为参与)描述了可以使用上面列出的任何技术来构建初始的、可能更高的错误系统的情况。但人工智能足够聪明,能够知道自己何时对某个标签有信心,并知道将其展示给人类专家,并在后一种情况下听从他们的判断。每次这样做,它也会向人类学习,从而随着时间的推移,提高输出的准确性和信心。
通过使用这些方法的组合,可以构建和部署经过10个示例训练的有效目视检查模型。用小数据构建系统对于突破数百万个只有小数据集可用的用例非常重要。对于制造商来说,这将使人工智能投入使用并创造实际价值所需的时间、工程工作量和数据降至最低。








